
Zhiyuan Ma is a postdoctoral fellow in the Department of Electronic Engineering at Tsinghua University  and a recipient of the National Natural Science Foundation of China Youth Fund. His co-supervisor is Professor Bowen Zhou (周伯文).
and a recipient of the National Natural Science Foundation of China Youth Fund. His co-supervisor is Professor Bowen Zhou (周伯文).
As the person in charge, he presided over a number of national natural science projects, postdoctoral general projects, and postdoctoral national funding plan projects, and also participated in a number of major projects of the Ministry of Science and Technology in 2030. He was also a member of ACL, ACM, CCF professional member, member of the Beijing BAAI-Qingyuan research group, and reviewer of top international journals and conferences such as TNNLS, ICLR, ICML, NeurIPS, ACL, EMNLP, COLING, NAACL, AAAI, AISTATS, ECAI, CIKM, etc.
He received his Ph.D. from Huazhong University of Science and Technology and graduated from the Huazhong University of Science and Technology one year ahead of schedule in June 2023 (the first doctoral student to graduate ahead of schedule). During his doctoral studies, he has won many honors, including Outstanding Doctoral Graduate, Outstanding Graduation Thesis, National Scholarship, Guanghua Scholarship, BIGO Enterprise Scholarship, Outstanding Graduate Student Cadre, Three Good Graduate Student, Zhiyin Pilot Student, Zhiyin Pillar Student Academic Research Award (the only one in the college), and won the Best Paper of the First Annual Academic Conference of HUST-CS in 2022.
His research interests include generative ai, natural language processing , embodied AI, vision and language , task-oriented dialogue systems , controllable generation and AI for Science . His main work has been published in the top international conferences of artificial intelligence and natural language processing, such as NeurIPS, ACL, EMNLP, AAAI, ACM MM, and COLING, as the first author. His work in the field of multimodal pre-training, CMAL, has been cited and positively evaluated by LeCun (Turing Award winner and Facebook Chief AI Scientist). This work innovatively proposed the pre-training method of cross-modal associative learning, and made new breakthroughs in modality-aligned vision-language pre-training.
If you like the template of this homepage, welcome to star and fork the open-sourced template version AcadHomepage 
🔥 News
- 2024.09: 🎉 Three papers are accepted by NeurIPS 2024, one of which is selected as Spotlight paper.
- 2024.08: 🎉 Received the news of the National Natural Science Foundation Youth Project Funding!
- 2024.07: 🎉 One paper is accepted by ACM MM 2024.
- 2023.12: 🎉 Three papers are accepted by AAAI 2024.
- 2022.11: 🎉 One paper is accepted by AAAI 2023 as Oral paper.
- 2022.08: 🎉 One paper is accepted by COLING 2022.
- 2022.06: 🎉 One paper is accepted by ACM MM 2022 as Oral paper.
- 2022.02: 🎉 One main track paper is accepted by ACL 2022.
- 2021.08: 🎉 Two papers are accepted by EMNLP 2021, one of which is the main track paper and the other is findings.
🧑🏫 Projects
- 2024.08: National Natural Science Foundation (NSFC) Youth Project (No.62406161), 国家自然科学基金青年项目.
- 2023.12: Nationally Funded Postdoctoral Researcher Program (No.GZB20230347), 国家资助博士后研究人员计划(B档).
- 2023.11: Fellowship from the China Postdoctoral Science Foundation (No.2023M741950), 中国博士后科学基金第74批面上资助.
📝 Publications
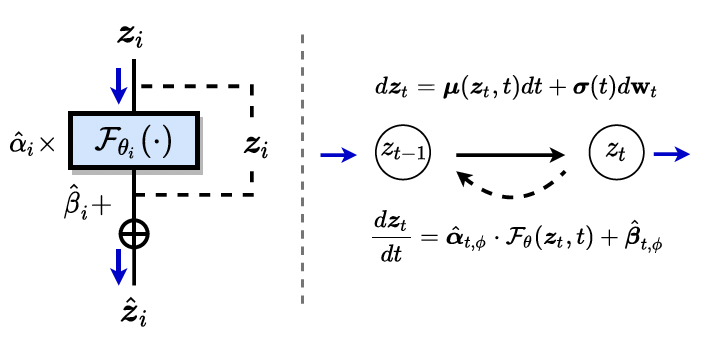
Neural Residual Diffusion Models for Deep Scalable Vision Generation
Zhiyuan Ma, Liangliang Zhao, Biqing Qi, Bowen Zhou
- a simple yet meaningful change to the common architecture of deep generative networks by introducing a series of learnable gated residual parameters that conform to the generative dynamics that facilitates effective denoising, dynamical isometry and enables the stable training of extremely deep networks.
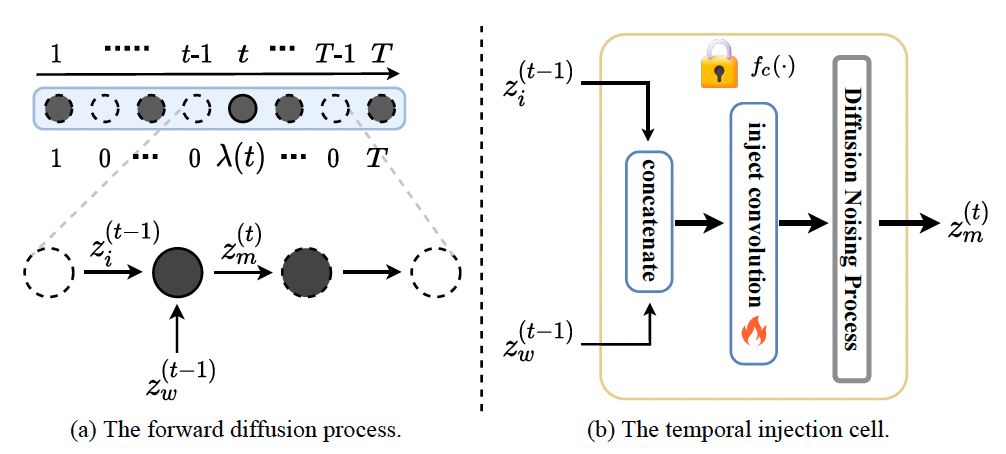
Zhiyuan Ma, Guoli Jia, Biqing Qi, Bowen Zhou
- A safe and high-traceable Stable Diffusion framework (namely Safe-SD) to adaptively implant the graphical watermarks (e.g., QR code) into the imperceptible structure-related pixels.
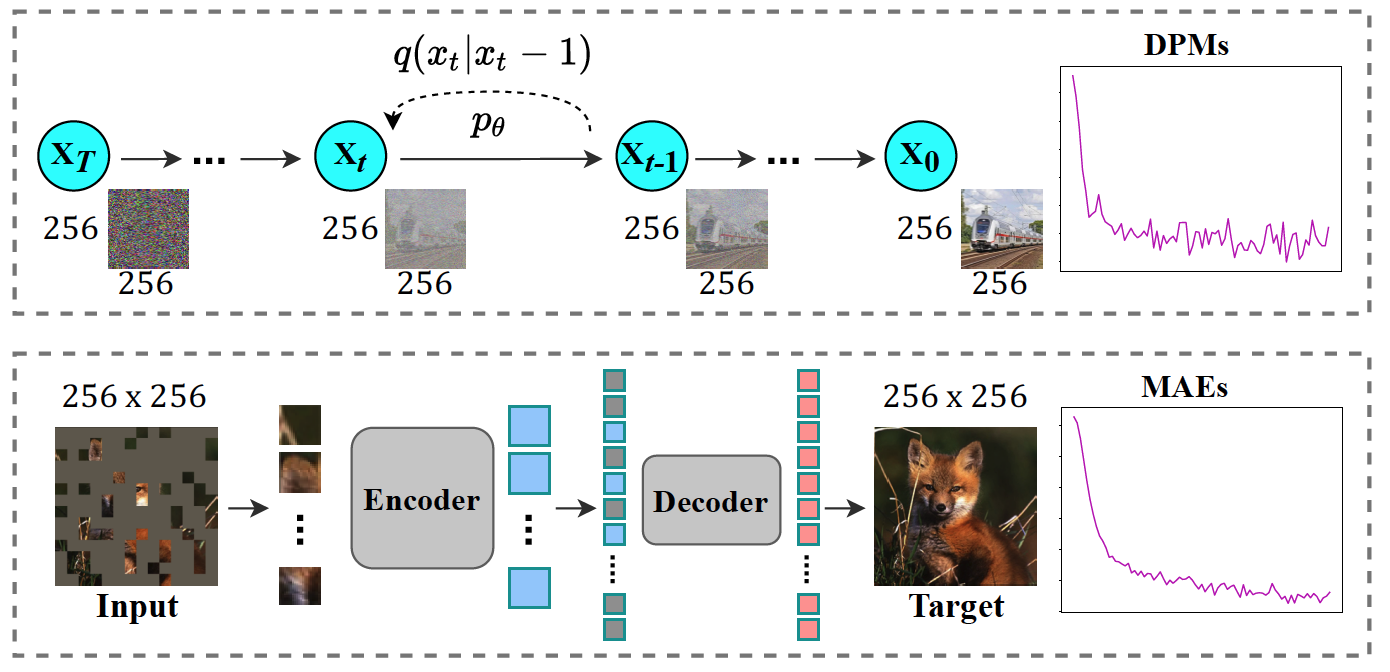
LMD: faster image reconstruction with latent masking diffusion
Zhiyuan Ma, Zhihuan Yu, Jianjun Li, Bowen Zhou
- A simple but faster image reconstruction framework with Latent Masking Diffusion, which stands on the shoulder of DPMs and MAEs.
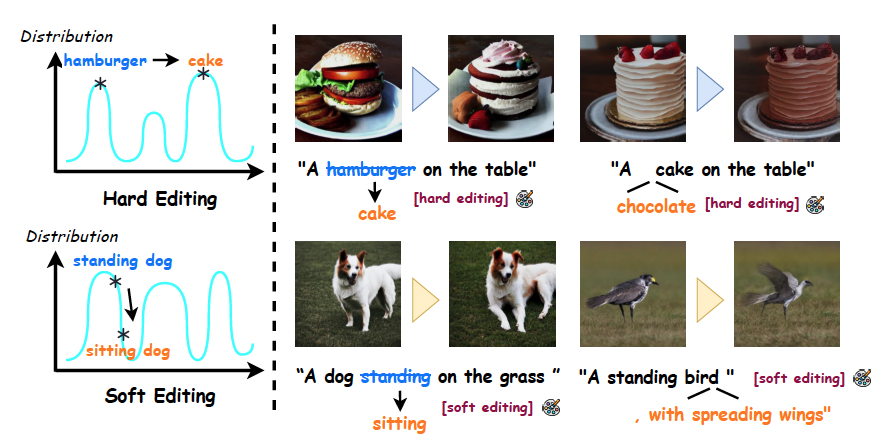
Zhiyuan Ma, Guoli Jia, Bowen Zhou
- A spatio-temporal guided adaptive editing algorithm, which realizes adaptive image editing by introducing a soft-attention strategy to dynamically vary the guiding degree from the editing conditions to visual pixels from both temporal and spatial perspectives.
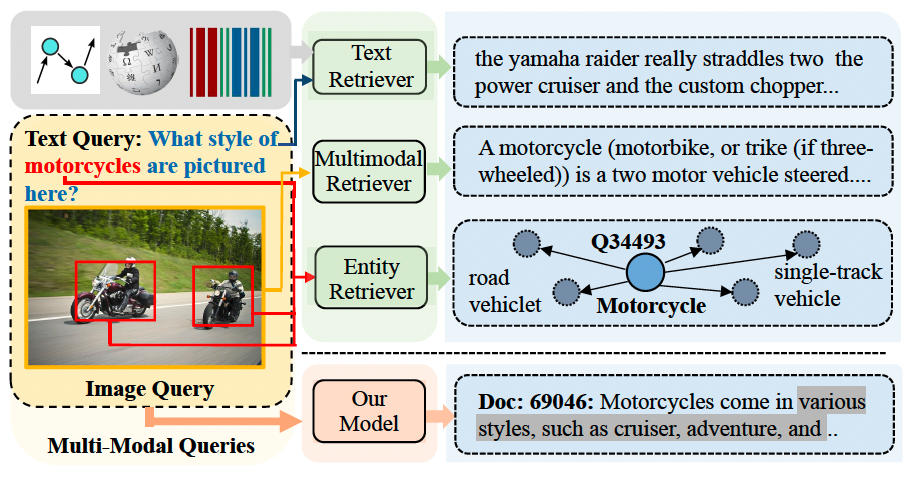
Generative multi-modal knowledge retrieval with large language models
Xinwei Long, Jiali Zeng, Fandong Meng, Zhiyuan Ma, et al.
- An end-to-end generative framework for multi-modal knowledge retrieval by taking advantage of the fact within LLMs can effectively serve as virtual knowledge bases, even when trained with limited data.
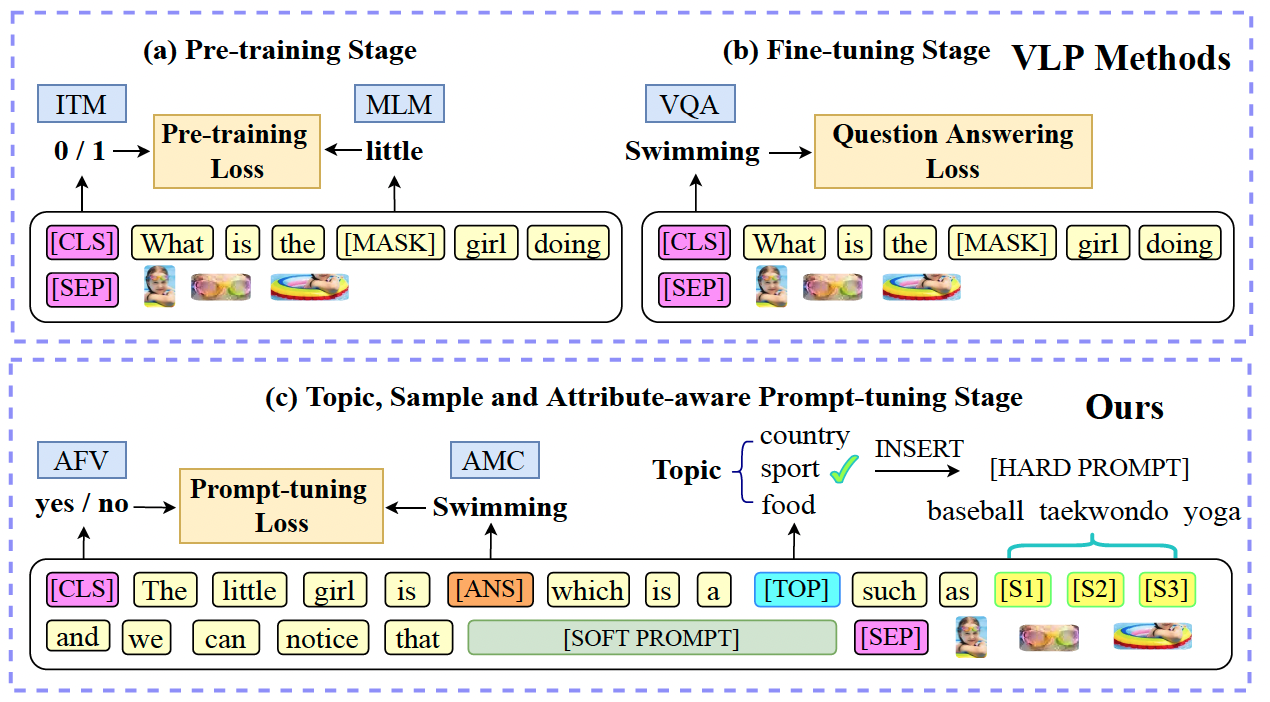
Zhiyuan Ma, Zhihuan Yu, Jianjun Li, Guohui Li
- A cloze- and verify- style hybrid prompt framework with bridging language models and human priors in prompt tuning for VQA.
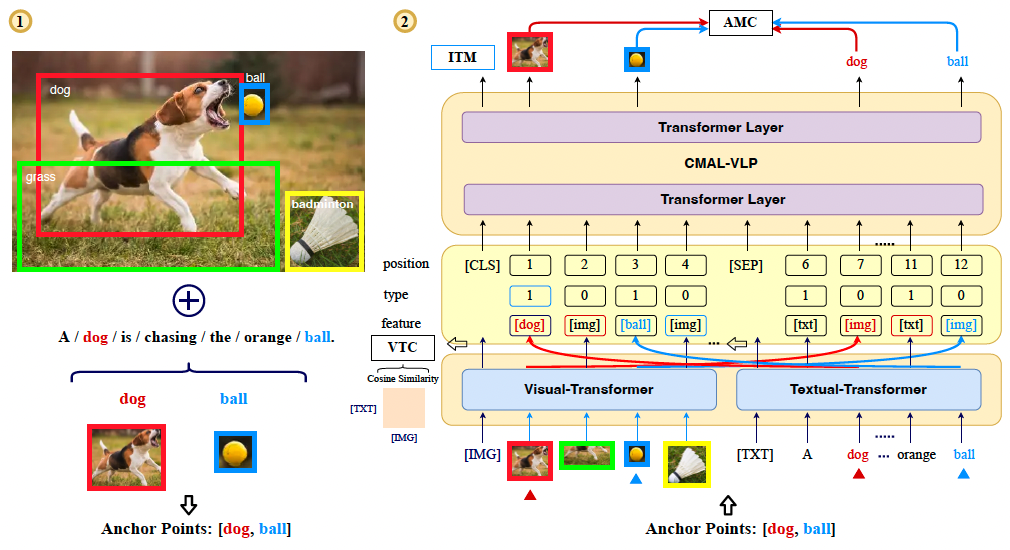
Cmal: A novel cross-modal associative learning framework for vision-language pre-training
Zhiyuan Ma, Zhihuan Yu, Jianjun Li, Guohui Li
- A novel cross-modal associative learning model with anchor points detection and cross-modal associative learning for vision-language pre-training.

GLAF: global-to-local aggregation and fission network for semantic level fact verification
Zhiyuan Ma, Zhihuan Yu, Jianjun Li, Guohui Li
- we introduce a fresh perspective to revisit the fact verification task and propose a novel Global-to-Local Aggregation and Fission Network (GLAF) to capture latent logical relations hidden in evidence clues for more accurate fact verification.
Zhiyuan Ma, Jianjun Li, Guohui Li, Yongjing Cheng
- A unified (vision, language, knowledge..) Transformer semantic representation framework with feature alignment and intention reasoning, referred to UniTranSeR, for multimodal task-oriented dialog systems.
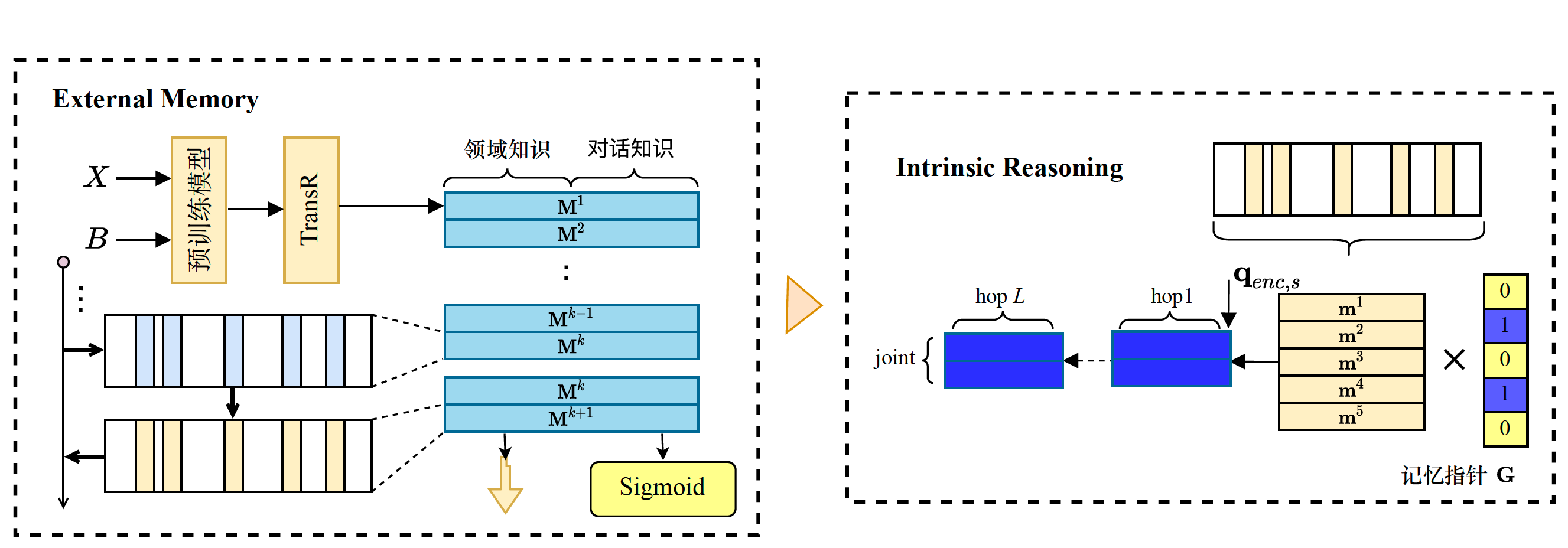
Intention reasoning network for multi-domain end-to-end task-oriented dialogue
Zhiyuan Ma, Jianjun Li, Zezheng Zhang, Guohui Li, Yongjing Cheng
- A novel intention mechanism to better model deterministic entity knowledge for joint and multi-hop reasoning in multi-domain end-to-end task-oriented dialogue.
📝 Selected Papers
NeurIPS 2024Neural Residual Diffusion Models for Deep Scalable Vision Generation. Zhiyuan Ma, Liangliang Zhao, Biqing Qi, Bowen Zhou.NeurIPS 2024(Spotlight) Ultramedical: Building specialized generalists in biomedicine. Kaiyan Zhang, Sihang Zeng, Ermo Hua, Ning Ding, Zhang-Ren Chen, Zhiyuan Ma, et al.NeurIPS 2024Exploring Adversarial Robustness of Deep State Space Models. Biqing Qi, Yang Luo, Junqi Gao, Pengfei Li, Kai Tian, Zhiyuan Ma, et al.ACM MM 2024Safe-SD: Safe and Traceable Stable Diffusion with Text Prompt Trigger for Invisible Generative Watermarking. Zhiyuan Ma, Guoli Jia, et al.AAAI 2024LMD: faster image reconstruction with latent masking diffusion. Zhiyuan Ma, Zhihuan Yu, Jianjun Li, Bowen Zhou.AAAI 2024AdapEdit: Spatio-Temporal Guided Adaptive Editing Algorithm for Text-Based Continuity-Sensitive Image Editing. Zhiyuan Ma, Guoli Jia, Bowen Zhou.AAAI 2024Generative multi-modal knowledge retrieval with large language models. Xinwei Long, Jiali Zeng, Fandong Meng, Zhiyuan Ma, et al.AAAI 2023(Oral) HybridPrompt: bridging language models and human priors in prompt tuning for visual question answering. Zhiyuan Ma, Zhihuan Yu, Jianjun Li, Guohui Li.ACM MM 2022(Oral) Cmal: A novel cross-modal associative learning framework for vision-language pre-training. Zhiyuan Ma, Zhihuan Yu, Jianjun Li, Guohui Li.COLING 2022GLAF: global-to-local aggregation and fission network for semantic level fact verification. Zhiyuan Ma, Zhihuan Yu, Jianjun Li, Guohui Li.ACL 2022UniTranSeR: A unified transformer semantic representation framework for multimodal task-oriented dialog system. Zhiyuan Ma, Jianjun Li, Guohui Li, Yongjing Cheng.EMNLP 2021Intention reasoning network for multi-domain end-to-end task-oriented dialogue. Zhiyuan Ma, Jianjun Li, Zezheng Zhang, Guohui Li, Yongjing Cheng.
🛡️ Patents
- 2024.04.19: 基于扩散模型的图像隐形水印嵌入检测处理方法及装置【CN117911230A】;马志远,周伯文,刘佐立
- 2024.06.14: 基于代码大语言模型的数据处理方法及装置【CN118194856A】;田锴,齐弼卿,马志远,周伯文
- 2024.07.12: 图像生成模型的微调训练方法及装置【CN118333125A】;袁振钊,谢树雷,马志远,李凯祥
- 2024.09.17: 视频生成模型的训练方法、装置、电子设备及存储介质【CN118658032A】;赵亮亮,谢树雷,马志远,丁宁,郑元春
🎖 Honors and Awards
- 2023.06: One of the best papers in the first HUST-CS annual academic conference.
- 2023.05: Zhiyin Pillar Student Academic Research Award (the only one in the college). (Top 1%)
- 2022.10: Doctoral National Scholarship Honors, Zhiyin Student Scholarship and Three Good Graduate Student Honors. (Top 1%)
- 2021.10: BIGO Enterprise Scholarship, Guanghua Scholarship, Outstanding Graduate Student Leader. (Top 1%)
🎓 Educations
- 2023.07 - 2025.07 (now), Postdoctoral fellow, Tsinghua University, Beijing, China.
- 2019.09 - 2023.06, PhD student, Huazhong University of Science and Technology, Wuhan, Hubei, China.
💻 Internships
- None